An Insightful Look into the Evolution of LLMs and GPTs
Written on
Chapter 1: Understanding the Landscape of LLMs
Recent insights from Yann LeCun, a leading figure in deep learning currently at Meta, provide a captivating visualization of the history and interrelations of large language models (LLMs). Despite his skepticism about GPT models, LeCun has shared a thoughtful diagram created by Jingfeng Yang from GitHub, which reveals the intricate heritage of numerous LLMs.
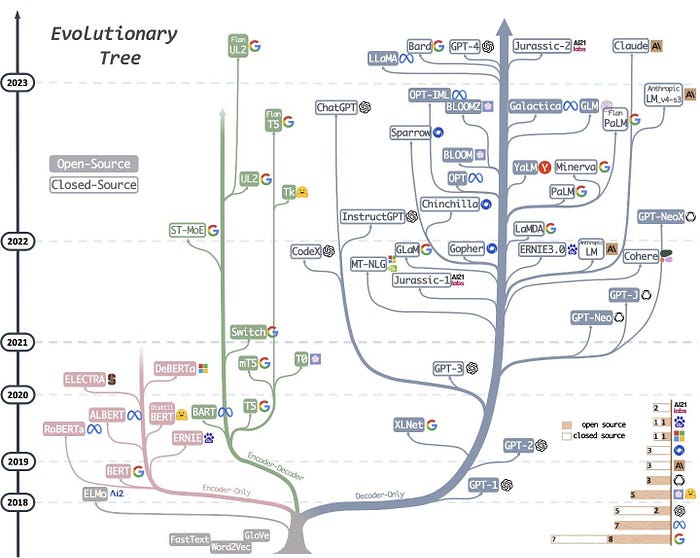
The chart illustrates a rich lineage of LLMs, showcasing over four dozen models, each contributing uniquely to the field. Interestingly, while Meta and Google seem to lead in terms of model releases, OpenAI’s GPT-4 is widely recognized for its superior performance compared to Google’s Bard, as evidenced by recent evaluations.
Section 1.1: The Roots of LLMs
The foundational models, such as Word2Vec, serve as the base for the evolution of LLMs. The visualization categorizes models into three primary architectures:
- Encoder-only models (e.g., BERT): These models focus on creating continuous vector representations of input text, capturing contextual information which is crucial for tasks like text classification and sentiment analysis.
- Decoder-only models (e.g., GPT): These models generate output text based on preceding context, making them ideal for text generation tasks such as storytelling or conversational AI.
- Encoder-decoder models (e.g., T5, BART): Combining the functions of both previous types, these models encode input into vector representations and then decode it to produce output, excelling in tasks like machine translation and summarization.
Subsection 1.1.1: Who Comes Out on Top?
In practice, the effectiveness of LLMs varies by application, but decoder-only models, particularly those using the Transformer architecture like the GPT series, consistently outperform their peers.
Section 1.2: Why Decoder-Only Models Excel
The success of models like GPT can be attributed to their unique architecture and extensive unsupervised pretraining. Their self-attention mechanisms excel at capturing long-range dependencies and contextual representations in text.
Unlike traditional static word vectors, which provide fixed representations, GPT uses a tokenization approach to convert text into sequences of tokens that reflect word or sub-word units. Each token is linked to dynamic embeddings that evolve based on contextual usage, enhancing the model's language understanding capabilities.
Chapter 2: The Advantages of Tokenization in LLMs
Decoder-only architectures like GPT generate text by predicting token distributions based on context. This process includes:
- Tokenization: Breaking down input text into manageable sequences of tokens.
- Embedding: Mapping tokens to learned embeddings that vary with context.
- Positional Encoding: Adding positional information to embeddings to maintain sequence order.
- Transformer Layers: Processing these enriched embeddings through multiple layers to refine relationships.
- Softmax Activation: Generating probability distributions to predict the next token in a sequence.
This innovative approach allows GPT to produce coherent and contextually relevant outputs, significantly advancing the field of natural language processing.
In summary, while all LLMs draw inspiration from earlier word vector models, the most effective ones, such as GPT and Bard, utilize token-based mechanisms instead of traditional vectors. This shift enables a deeper understanding of linguistic nuances, context, and relationships, paving the way for future advancements in AI and language technologies.
Stay tuned for more exciting developments in multi-modal LLMs, which promise to integrate images and data seamlessly into their outputs.