Understanding Self-Supervised Learning: A Comprehensive Guide
Written on
Chapter 1: Foundations of Learning Methods
In the realm of machine learning, two prominent methods are supervised and unsupervised learning. Nestled between these approaches is self-supervised learning, a technique that addresses intriguing challenges.
To grasp the concept of self-supervised learning, it’s essential to first clarify the principles behind supervised and unsupervised learning.
Section 1.1: Supervised Learning Explained
In supervised learning, we work with a dataset consisting of inputs and corresponding labels, often referred to as ground truth. Using this data, we can train models—such as decision trees or neural networks—to correlate inputs with their respective labels, which function as guidance for the model.
After proper training, these models can then predict labels for new, unlabeled data. Common tasks associated with supervised learning include classification and regression.
Section 1.2: Unsupervised Learning Overview
In contrast, unsupervised learning deals with data devoid of labels, meaning there is no guidance available. Despite this, several tasks can still be performed on unlabeled data, such as identifying similarities, segmenting data, and clustering it into distinct groups.
Section 1.3: Introducing Self-Supervised Learning
The real world is filled with vast amounts of unlabeled data—ranging from text to images and audio—and this volume is rapidly expanding. Labeling this data is a labor-intensive process, making it impractical to do so for the large datasets required for effective training.
So, how can we leverage this unlabelled data? Self-supervised learning provides a solution by generating labels from the data itself, allowing the model to learn through these self-created labels.
Example: Predicting Masked Words
Consider a scenario where we have unstructured text data. We can randomly mask certain words within this text and train the model to predict these masked words. Here, the unmasked sentences serve as inputs, while the masked words become the labels for the model to predict.
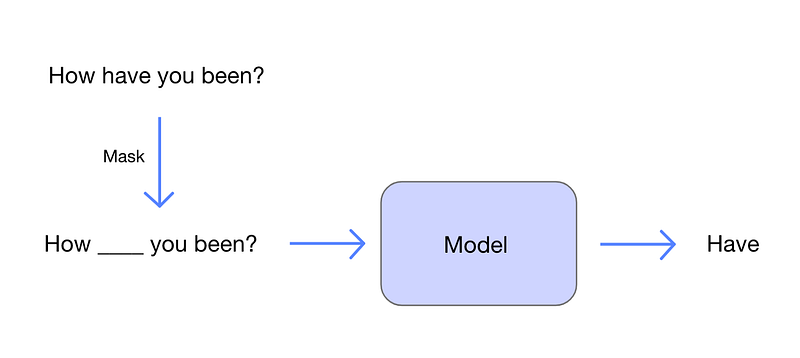
For the model to accurately predict the masked words, it must grasp the nuances of language representation and the context of sentences, which it learns over time. This capability illustrates the elegance of self-supervised learning, where the model acquires knowledge without the need for human-annotated data.
Section 1.4: The Pre-training Process
Training a model through self-supervised methods is often termed pre-training. A significant advantage of this approach is the elimination of the need for manual labeling, thus avoiding data shortages.
Once the model undergoes pre-training, it can be fine-tuned for specific downstream tasks, such as classification or regression. The foundational knowledge gained during pre-training enables the model to adapt to these tasks more swiftly, often requiring less labeled data.
Pre-trained Language Models
An excellent example of a pre-trained model is BERT, which initially learns to predict masked words and subsequently determines if a given sentence logically follows another. This pre-training equips BERT to tackle downstream tasks more efficiently with minimal data.
Another prominent model, GPT-2, is pre-trained to anticipate the next word in a sentence based on preceding words.
Section 1.5: Self-Supervised Learning in Image Data
Just as we can pre-train models on textual data, image data can also be subjected to self-supervised learning. Through this process, models learn to comprehend the underlying characteristics of images.
For instance, similar to word masking, we can randomly obscure a portion of an image and train the model to predict the missing patch.
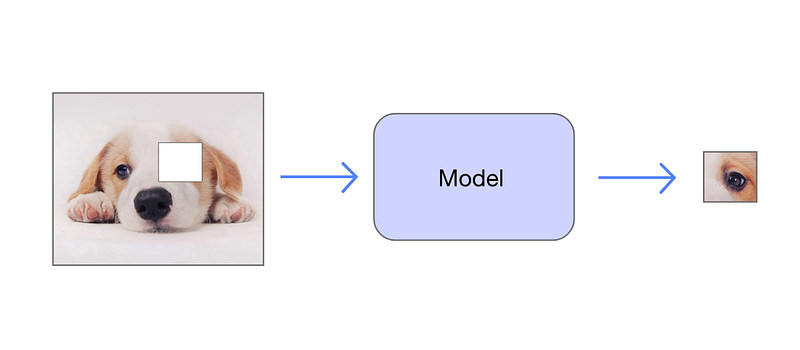
To successfully learn this task, the model must understand various elements within images, including objects, backgrounds, and color schemes. Upon completion of pre-training, the model can be effectively trained for downstream tasks like image classification.
Additional Pre-training Tasks
We can also define various tasks for image pre-training, such as:
- Randomly rotating images and predicting the angle.
- Transforming colored images to grayscale and learning to restore color.
- Blurring images and training the model to enhance clarity.
- Rearranging image segments like a puzzle and training the model to solve it.
Section 1.6: The Power of Contrastive Learning
Among the pre-training tasks, contrastive learning stands out for its effectiveness. This method involves augmenting images derived from a source image through various transformations, such as cropping, color adjustments, and resizing.
When two images originate from the same source, they are termed a positive pair; otherwise, they are negative pairs. The model is trained on these pairs to learn to produce similar vector representations for positive pairs.
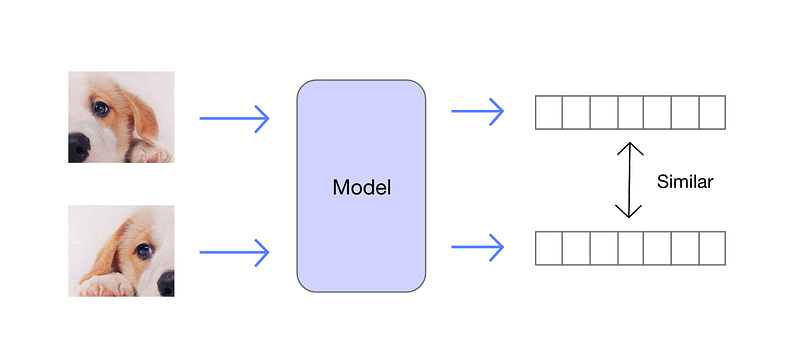
If the model excels at this task, it demonstrates an ability to identify similar images without needing explicit labels, indicating a robust understanding of the data.
Summary: The Promise of Self-Supervised Learning
The remarkable achievement of self-supervised learning lies in its ability to train models to comprehend data without any annotations. Once this understanding is established, these models can be applied to a variety of downstream tasks.
Even in scenarios where downstream applications are not the focus, self-supervised learning can address challenges such as image colorization, masked word prediction, and image denoising. Ultimately, self-supervised learning represents a significant stride toward achieving general artificial intelligence.
Explore the fundamentals of self-supervised learning and its implications in the field of AI with this insightful video.
Delve deeper into the concept of self-supervised learning and its various applications through this informative video.