Revolutionary Text-to-Speech Model Achieves New Heights
Written on
Chapter 1: Introduction to Multimodal Models
Recent advancements in training multimodal models, particularly for text-to-speech applications, have revealed notable challenges. A significant issue arises from the mismatch in sequence lengths between high-sample-rate audio and corresponding text. This research aims to tackle these discrepancies without necessitating the generation of meticulously annotated training data.
Section 1.1: The Challenge of Sequence Length Mismatch
The application of cross-modal representation spaces, which align text and audio, has been a focus of research in Automatic Speech Recognition (ASR). Traditional models often require specific adaptations to accommodate the length differences between speech and text, either through up-sampling methods or dedicated alignment models. In our findings, we suggest that joint speech-text encoders can effectively manage these differences by ignoring the sequence lengths altogether.
Subsection 1.1.1: Visualizing the Alignment
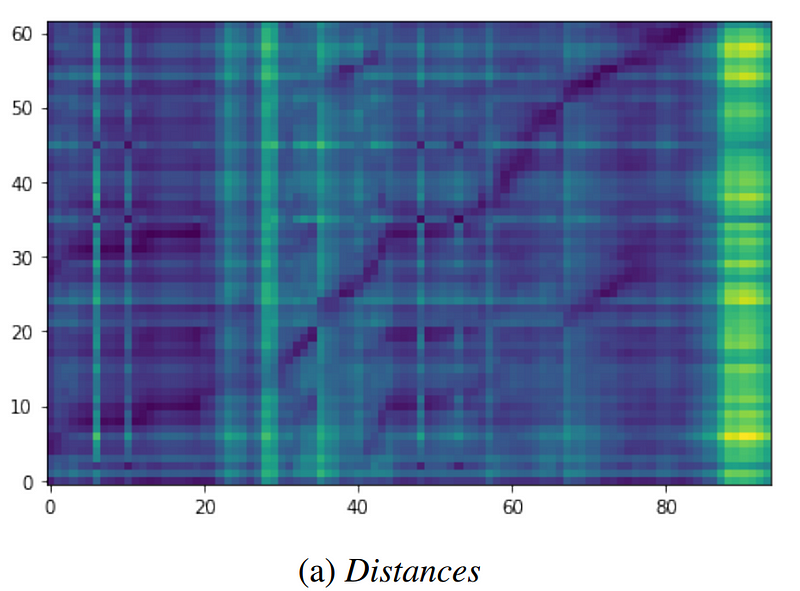
We provide compelling evidence that maintaining consistent representations across modalities can be achieved by disregarding the inherent length disparities. By employing consistency losses, we can improve the downstream performance metrics, such as the word error rate (WER), in both monolingual and multilingual systems.
Section 1.2: Methodological Framework
To address the challenges of training, we propose a dual-task model that processes both audio and text concurrently. The audio encoder analyzes audio input while the text encoder uses unpaired text samples. The training process incorporates masked text reconstruction, allowing the model to learn effectively even with incomplete data.
Chapter 2: Model Specifications and Training Process
The architecture of our model consists of a robust audio encoder featuring a conformer layer with multiple attention heads. This encoder processes log-mel spectrograms to create refined representations. The text encoder is designed to complement the audio encoder, forming a cohesive framework for audio-text alignment.
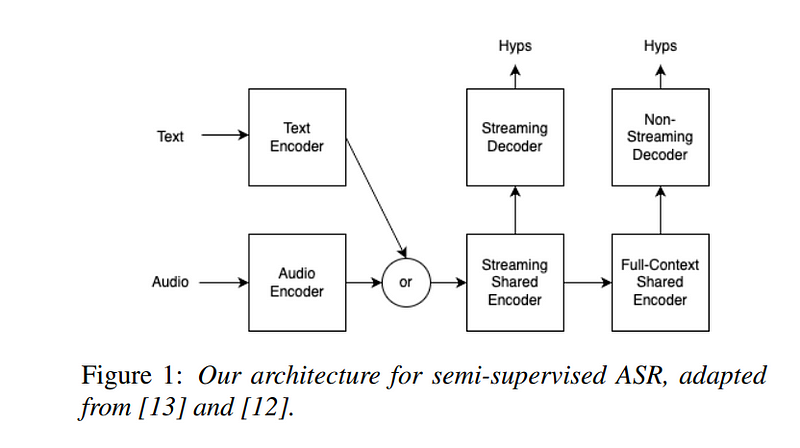
Training proceeds in two distinct phases, utilizing a vast dataset comprising both supervised and unsupervised examples. Our multilingual corpus includes data from eleven languages, enabling the model to generalize effectively across diverse linguistic contexts.
Results and Insights
The results indicate a strong alignment performance, with improvements in WER metrics, particularly in multilingual settings. The data suggests that our approach enhances the model's adaptability, leading to greater accuracy in speech recognition tasks.
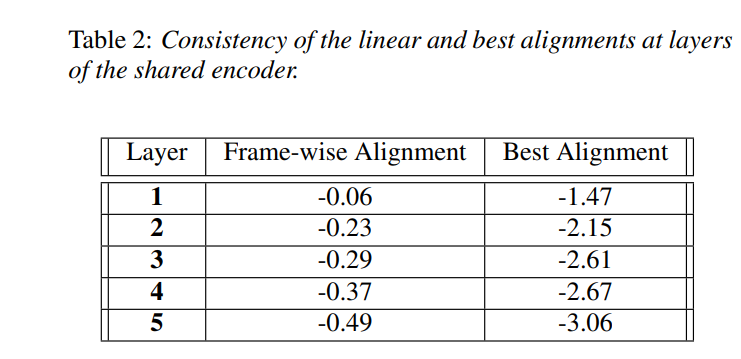
In the context of English-only datasets, the model shows consistent, albeit smaller, enhancements. However, in multilingual scenarios, the improvements are significantly pronounced, highlighting the model's robustness in handling complex linguistic challenges.
Conclusion: A New Paradigm in Speech Recognition
In conclusion, our semi-supervised approach to training a joint text-speech encoder has demonstrated the potential to optimize modality matching through enhanced alignment techniques. By integrating a consistency loss term, we achieve significant performance improvements without increasing model complexity.