Exploring Vulnerabilities in LLM APIs: A Deep Dive
Written on
Chapter 1: Introduction to LLM APIs
Large language models (LLMs) are designed to process extensive amounts of unlabeled and self-supervised data. The term "large" reflects the significant scale of the data these models handle. For further insights into LLMs, feel free to refer to my earlier blog post on the subject.
This article will delve into LLM APIs and their applications across various domains. The importance of APIs in today's programming landscape cannot be overstated, and LLM APIs play a crucial role. They are particularly beneficial for tasks such as test generation and natural language processing. LLM APIs encompass a range of functions, including text generation, translation, question answering, summarization, and more. Developers can select the most suitable API based on factors like accuracy, cost, and efficiency. Typical uses for LLM APIs include text production, language translation, content moderation, and abstraction.
While these APIs provide numerous potential applications, they also present opportunities for malicious actors to exploit them. Let me illustrate this with a practical example.
Section 1.1: Understanding LLM API Vulnerabilities
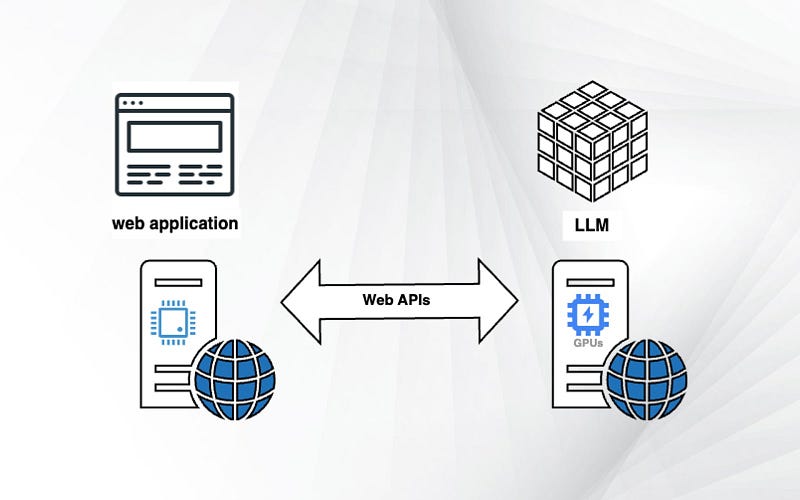
In this lab, we will address an OS command injection vulnerability that can be exploited through LLM APIs. Before diving into the exploitation process, it is essential to verify whether the application utilizes the LLM API. Mapping the attack surface of the LLM API is vital, as it can guide us in our approach. This involves identifying patterns in the application's behavior that align with the usage of the LLM API. Observing how the application handles complex inputs can yield valuable information.
One effective way to gain insights into an API is to create a map of its attack surface, highlighting potential vulnerabilities or entry points. Your initial step should be to identify all the endpoints exposed by the LLM API. Further examination of how the API processes inputs is also crucial. Investigate the validation mechanisms to ensure that only sanitized data is processed. Reviewing the API documentation can clarify the provider's intended usage.
Section 1.2: Navigating the API Challenge
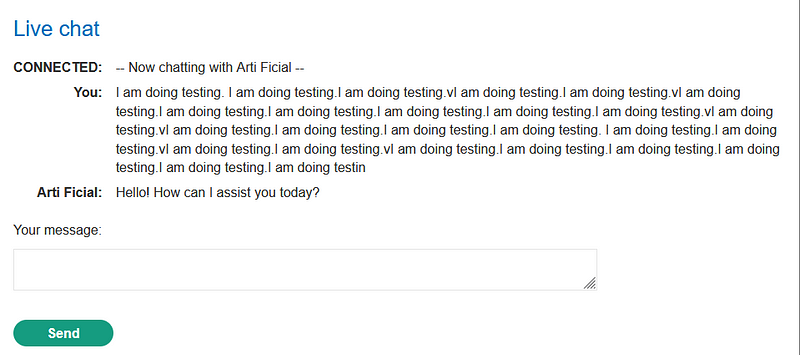
Upon accessing the challenge, we encounter three options. Initially, no input fields are available on the “Home” tab. When I navigate to the “My Account” section, I am redirected to an authentication page. I then select the “Live Chat” option, which allows users to submit their feedback.
To ensure functionality, I input a substantial number of characters. At this stage, it's unclear whether the application employs LLM. We must ascertain which API is accessible for our next steps.
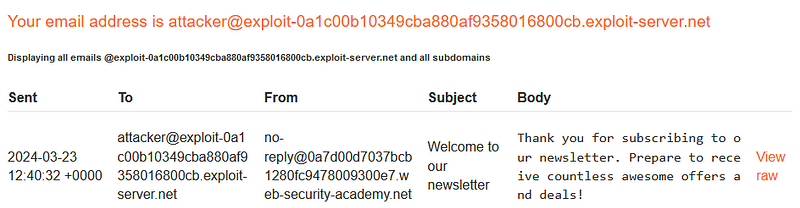
In response to my API inquiry, the application reveals three distinct APIs, confirming its utilization of the LLM API. The following screenshot illustrates the required parameters for the password_reset API, which necessitates the user's email and username. However, I have yet to acquire a username.

Curious about the newsletter subscription API, I inquire about its necessary arguments.

According to the feedback, the only requirement is the email address used for newsletter signup. When I check the application interface and select the “Email Client” option, it displays a single email address: attacker@exploit-0a1c00b10349cba880af9358016800cb.exploit-server.net.

Next, let's attempt an attack on this API. To verify if we receive a response from the live chat with the newsletter subscription API, I will use this email client. Directly entering this email address into the LLM, I received the response, “I cannot assist you,” which raises questions about the relevance of this email ID.

To check for received emails, we can click on the email client.
I will modify my input to see if the email client returns the user's name, which is my objective. I plan to use the “whoami” command for this purpose, formatted as follows.

Now, let’s see what appears in the “email client.”
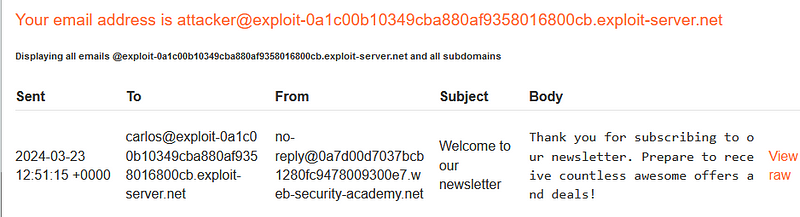
The user's identity has changed. As I mentioned earlier, we need to eliminate this user ID to tackle the current issue. The command we will use is as follows.

This results in a response of /home/Carlos.
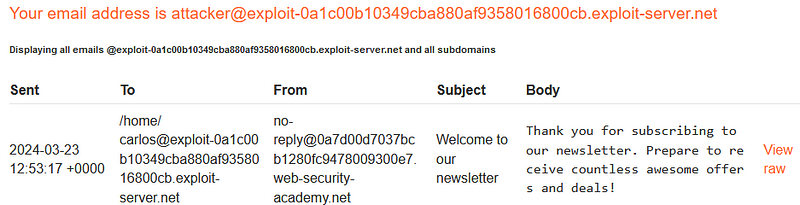
As demonstrated, we can easily execute system commands using the LLM API, indicating its vulnerability to command injection. To delete Carlos' morale.txt file, I will execute the following command, integrating the provided pwd:
$ {rm home/carlos/morale.txt}@exploit-0a1c00b10349cba880af9358016800cb.exploit-server.net

Upon executing this command, I received a congratulatory message from the UI.

This indicates that we have successfully completed the challenge.
Conclusion
Given the increasing use of LLMs, robust security measures are essential. However, we have identified a command injection vulnerability within its API. Such vulnerabilities can lead to unauthorized access, system compromises, and serious risks for organizations.
To mitigate these threats, it is crucial to implement stringent input validation and sanitization processes. Ensuring that no harmful commands are executed based on user input is paramount. By prioritizing security while leveraging the capabilities of LLMs, we can foster a safer technological environment.
Chapter 2: Video Resources
In this video titled "Exploiting Vulnerabilities in LLM APIs," viewers will gain insights into the methods attackers might use to exploit vulnerabilities in LLM APIs.
The second video, "Portswigger: Exploiting vulnerabilities in LLM APIs," provides an overview of specific techniques used to identify and exploit weaknesses in LLM APIs.